
数据冷知识:为什么身分证字号会重复?有什么影响?

不管你是使用 Ragic、其他数据库系统或其他工具管理数据,可能都会听到大家在谈“Key 值”/“独特值”(unique value)字段的重要性。
简单来说,就是在存放数据时,不管是客户数据、订单数据、还是请购单纪录等等,每一笔数据上面都应该要有一个“专属于那笔数据、独一无二的标号”,没有的话也要新增/分配一个,例如客户编号、订单编号、请购单编号。
有了标号,才能让人依据这个标号来找到、指认这笔数据,就像每笔数据都要有一个门牌号码,或是每笔数据都要有一个身分证字号一样。(相关文章可以参阅这里)
等等...说到“身分证字号”,它虽然是一个用来解释 Key 值的好用概念,实务上也可能有人用它来当会员数据的识别依据,但你知道台湾有很多人身分证字号是跟别人重复的吗?
如果你跟别人身分证字号重复,会发生什么事?
“身分证字号怎么可能重复?”原本我也是这样想的,但 Google 输入“身分证字号 重复”,你会发现网络上已经有一堆案例:无故收到不属于自己的补税单、罚单、银行信用被严重影响、办护照被卡关、补助被撤销等等,都因为事主的身分证字号和别人重复,银行、政府机关“认错人”导致的。
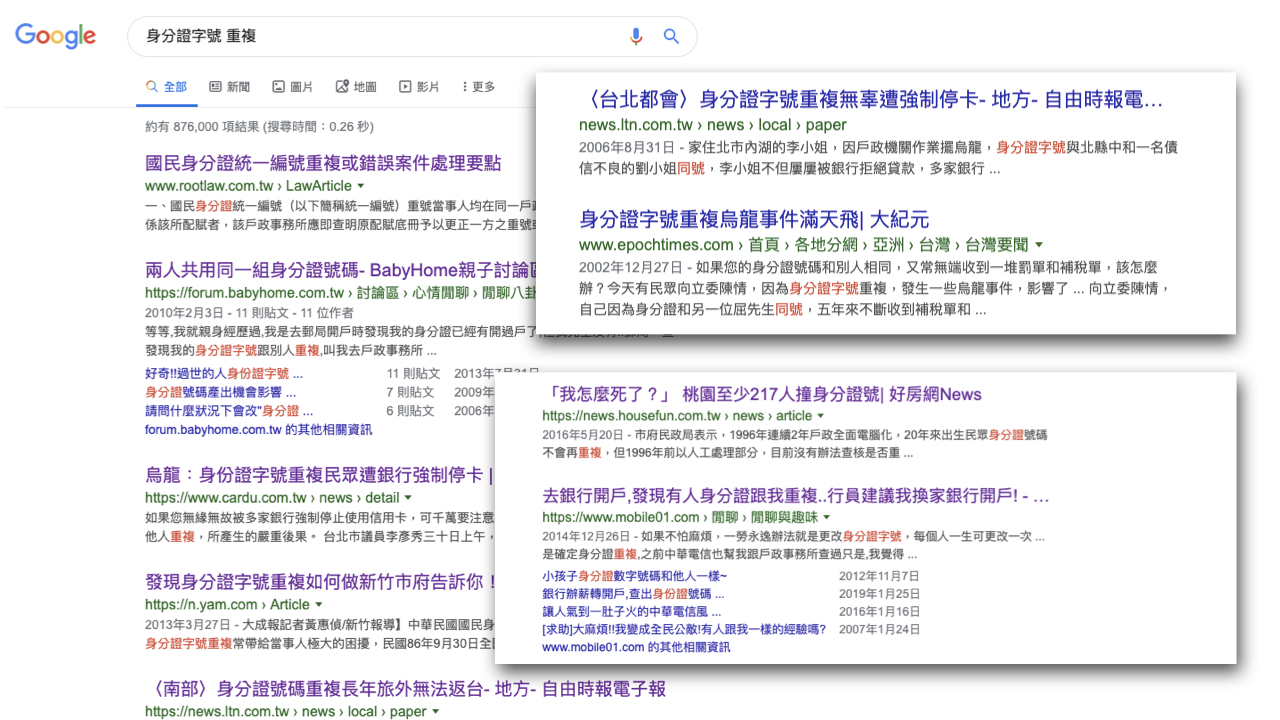
身分证字号重复的原因
身分证重号现象的主因,是 1995 年台湾户政计算机化前,打印件抄录出错造成的“历史共业”。
台湾的身分证统一编号制度民国 54 年就开始实现,起初的几十年,户政机关都是以人工抄写的方式登记户籍、身份数据甚至制作身分证,只要抄写员一时笔误或字迹潦草让人认错,就会无意间造成身分证字号重复。
而因为工作流程没有计算机化,数据都是以打印件形式散放在各地户政事务所中,没有大规模调查,新竹的户政事务所不会确知台北有哪些数据,错误默默衍生后,要比对全国数据、掌握错误并更正也不容易,这些重号的身分证数据就一直存在户政系统中。
90 年代台湾户政业务开始逐步计算机化,1995 年各地户政事务所开始将打印件数据登录到计算机中、启动县市联机操作,各县市户政事务所过去散落的数据从此可以联机查看、比对,过去潜伏鲜为人知的“同号问题”马上浮出水面。
根据 1996 年并报的报导,当时光是新竹市第一户政事务所和其他七个县市联机后,辖区内就查出千余件身分证字号“同号”现象。(当时还有户政人员转述老一辈说法表示,民国 75 年政府全面换发身分证时,也曾藉着大规模替换操作掀开这个“同号问题”,统计出全台有 28 万件身分证统号重覆,不确定数字是否精确,但跟户政人员的经验相符。-- 此段数据来源为 1996/08/27 并报07版的报导)
而“身分证同号现象”被发现后,并没有马上一一解决,留存至今,2016年桃园市税务局仍然查出全市有217人税籍身分证重号。
在数据管理上的意义:别拿身分证字号当 Key 值!
身分证重号不只是“重号苦主”才要面对的问题,对需要负责客户数据管理、会员数据管理、员工数据建檔的人来说,这件事代表着不能默认“台湾的身分证字号是独特值”,因为可能重号,一但你的系统中把身分证字号字段设成识别数据的 Key 值字段,你就会跟那些寄错税单、罚单、法院传票的人一样,把 A 客户和 B 客户搞混。
最近信息业的话题 -- 南山人寿的新系统“境界计画”上线乱象,也牵涉到身分证字号重复问题,而天下杂志的这篇报导中针对这一点特别提到,许多做金融业系统的人都知道要在设置订户ID时,在身分证字号后加上辅助码(等于不直接将身分证字号当成辨认订户的 ID),这是一个避免问题的方法。
最保险的方法是,在设置独特值字段时,尽量不要使用外来数据,以自己内部生成的编码为主,因为外来数据毕竟不是自己可以 100% 掌控的。Ragic 的自动生成字段值功能就很适合创建这种编码字段。

